Table of Contents
Scaling issues are problems that arise when a system or application is unable to handle exponentially larger amounts of data or user traffic. We recently wrote about how freemium nearly caused our business to implode due to such scaling issues. This is a true tale of why scaling an app is never as easy as it seems.
Building software is sorta like a bright-eyed and bushy-tailed camp counselor. At first, kids are dropped off by their parents, one or two at a time. Each kid has some special request that has to be handled. One has a ton of luggage to be stored. Another is a vegan. Another just wants to do archery and nothing else.
That’s fine.
Then, busloads of kids start getting dropped off — all who are camping for free, but all have luggage, dietary constraints, planning issues. Not fun.
By the end of the day…the poor counselor is toast.
Software and camp counselors have so much in common.
The trail of good intensions
- Write your app in Rails and use Postgres — Everything is great!
- Add a simple webhook for Stripe in Rails as a controller in the main app — We’re kicking!
- Start calculating in the background — use Sidekiq — Still great!
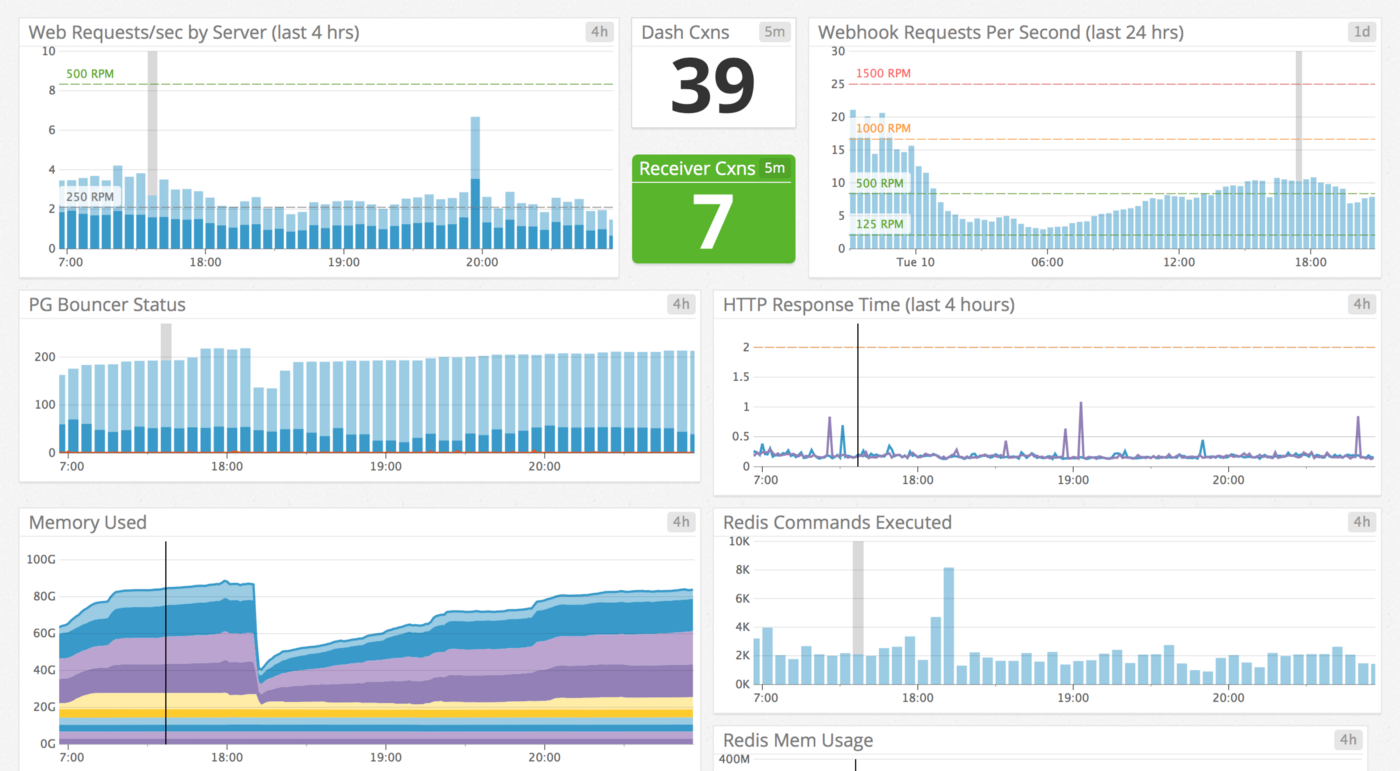
- Until a customer signs up that sends up 20,000+ events within a 24 hour period.
- Now, that simple webhook is causing the main dashboard to be slow
- Pull the webhook out into its own little microservice — it’s been running for months without intervention…
- Importing data from Stripe by months works great until a customer signs up with 8,000 events in a single day.
- Now we have to import by segment (2–3 days of movement forward lost)
- In that same time, more accounts sign up, we need more workers… no worries, crank them up!
- But wait, high memory workers on Heroku quite literally cost an arm, leg, kidney and first born.
- We’re a bootstrapped business, we can’t afford to spend this. Time to move to AWS. That’s totally reasonable.
- Eeeek, now pulling data down for local testing becomes nearly impossible, which slows development. Sigh.
- Worker issues solved.
- Oh, but PG has a connection limit issue hardly worth mentioning…
- Fine, fire up pgbouncer on each machine
- Fantastic! That works, until it doesn’t — finally move pgbouncer to it’s own machine — connection issues resolved
- Oh, but in the meantime, the queries on the DB server are killing the CPU
- In that case, pull out a high traffic table into its own separate DB
- Well hot dog, there are connection limit issues with the new DB (repeat lessons learned previously)
- Oh, someone signed up with 4,000 plans — all our per-plan workers are dying.
- In the meantime, marketing material in main app works great initially
- Until the marketing actually works and 1,000’s of people go to look at it
- Which kills main dashboard response time for paying customers
- Which means we have to quickly split the marketing site and app in to separate pieces
- And on and on it goes…
We couldn’t have known about any of this in the beginning. Sure, we could have assumed it, but then we’d also have never launched the product in the first place because we’d be spending all eternity optimizing for scale we didn’t have.
Building and, more importantly, shipping software is about the constant trade off of forward movement and present stability.
Silicon Valley is filled with graves of startups that never actually shipped anything because they were bent on fixing problems they didn’t have. Shipping is better than dying before ever leaving the runway. And yes, I’m aware that’s a clunky metaphor. But at least I shipped it. 🙂